


Es pronto para poder analizar y realizar observaciones reales sobre el buscador.
Habrá que ver si realmente harán sombra al gigante, cambiar los hábitos del usuario es la tarea más difícil aunque es el momento mas idóneo debido a la cada vez más apariencia de monopolio por parte de Google.
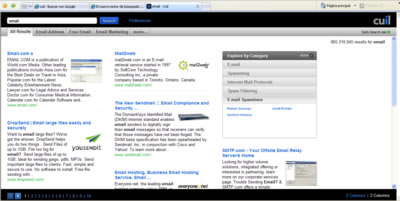
Por lo pronto la página de resultados de la web tiene un aspecto diferentes a las de Google. Analiza los conceptos en la página y sus relaciones y agrupa resultados similares en diversos menús
Cuil, ha sido presentado hoy y, como os contamos en su día, está liderado por grandes expertos mundiales en la tarea de indexar la información contenida en miles de millones de documentos web.
Anna Patterson y Russell Power, antiguos responsables del buscador web de Google, además del misterioso proyecto ‘TeraGoogle‘, el cual pretendía supuestamente ofrecer información histórica de todas las páginas indexadas por Google a lo largo de los años. Patterson, además, había creado antes de ser fichada por Google el buscador ‘Recall’ para el proyecto ‘archive.org‘.
:: Luis Monier, fundador del histórico buscador Altavista, antiguo responsable de I+D en eBay, y fichado por Google en junio de 2005 para crear un buscador «multifaceta».
:: Tom Costello, el creador del primer prototipo del proyecto ‘WebFountain de IBM, que persigue desarrollar buscadores de tercera generación.
«Nuestros significativos avances en la tecnología de búsqueda nos han permitido indexar mucho más de Internet, colocando casi toda la Red al alcance de los dedos de cada usuario», afirma en un comunicado Tom Costello, cofundador y consejero delegado de Cuil.
De inicio, tal y como se puede ver en la página inicial de Cuil (se pruncia como la palabra «cool», es decir ‘kül’), este buscador parte con más de 121.000 millones de páginas web indexadas, lo que ofrece una idea de la potencia de este nuevo proyecto. El pasado día 25 de julio os contábamos cómo Google había anunciado que su buscador tenía «procesadas» un billón de URLs. Si fuesen cifras que representan el mismo concepto, Google tendría 8.26 veces maś que Cuil. Pero, como os comentábamos, cada página web indexada puede representar por ejemplo a unas 10 URLs procesadas que ofrecen el contenido duplicado.
En estos momentos, debido a la elevada carga que están sufriendo los servidores de Cuil durante este día de lanzamiento, las páginas de resultados de Cuil suelen fallar frecuentemente, pero en algunas ocasiones (ver ejemplo) vemos cómo la calidad de los resultados puede mejorarse, pero también cómo se han incorporado algunas funcionalidades que no tienen otros buscadores como Google, como la de organizar los resultados por categorías, lo que permite que, por ejemplo, si buscamos la palabra ‘apache’ nos distinga entre el páginas relacionadas con el popular servidor web, o con la tribu india americana.
Para ofrecer la relevancia de las páginas web que muestra como resultados, Cuil no utiliza un algoritmo como PageRank que establece una ‘popularidad’ para cada documento, sino que analiza los contenidos de todas las páginas y, establece si una determinada página se adecúa a las palabras que escribió el usuario en el buscador.
Además, Cuil promete en esta página web que, cuando realizas una búsqueda en él, no se guarda ninguna información que pueda ser fácilmente indentificable. «No tenemos ni idea de quién realiza la búsqueda: ni su nombre, ni su dirección IP, ni sus cookies», aseguran. Esto, sin duda, será una gran baza de márketing de Cuild, frente a un Google sí que guarda parte de esta información, y que en alguna ocasión ha defendido el almacenamiento de direcciones IP de los usuarios alegando que «no se trata de un dato personal«.
Danny Sullivan, analista de búsquedas en Internet y editor jefe de Search Engine Land, cree que Cuil puede intentar explotar las quejas que los consumidores tienen de Google, principalmente por los resultados que favorecen a las páginas más populares.
Emprendedor, Seo, networker, domainer, padre.......
Un 30% talento y 70% restante energia positiva, la clave del éxito.